Effective Techniques to Clear Host Errors in Ansible Playbooks
By Luca Berton · Published 2024-01-01 · Category: troubleshooting
Discover practical methods to handle and clear host errors in Ansible, ensuring smooth automation and effective error management in your infrastructure.
Handling Host Errors in Ansible
In any automation system, handling errors efficiently is crucial to ensure smooth operations. Ansible, a popular IT automation tool, provides several mechanisms to manage errors during playbook execution. One common scenario is the need to clear or handle host errors to maintain an efficient and error-free automation environment. Below, we'll explore the strategies to manage host errors effectively in Ansible, including retry mechanisms, failure conditions, and error handling practices.
See also: Ansible Automation: Complete Guide to IT Automation with Playbook Examples
Understanding Host Errors
Host errors in Ansible typically occur when there is an issue connecting to a host or executing a task on a host. These can include connection failures, unreachable hosts, task failures, or issues with privilege escalation. Ansible marks these hosts as "failed" and, by default, will not proceed with subsequent tasks for those hosts unless instructed otherwise.
Strategies to Clear Host Errors
- Ignore Errors Using
ignore_errors:
ignore_errors directive. This is useful when you want the playbook to continue executing even if a particular task fails.
- name: Attempt to stop a non-existent service
service:
name: non_existent_service
state: stopped
ignore_errors: yes
- Handle Failed Hosts with
rescueandalways:
block, rescue, and always directives provide structured error handling. rescue runs if there is a failure within a block, and always runs regardless of the block’s outcome.
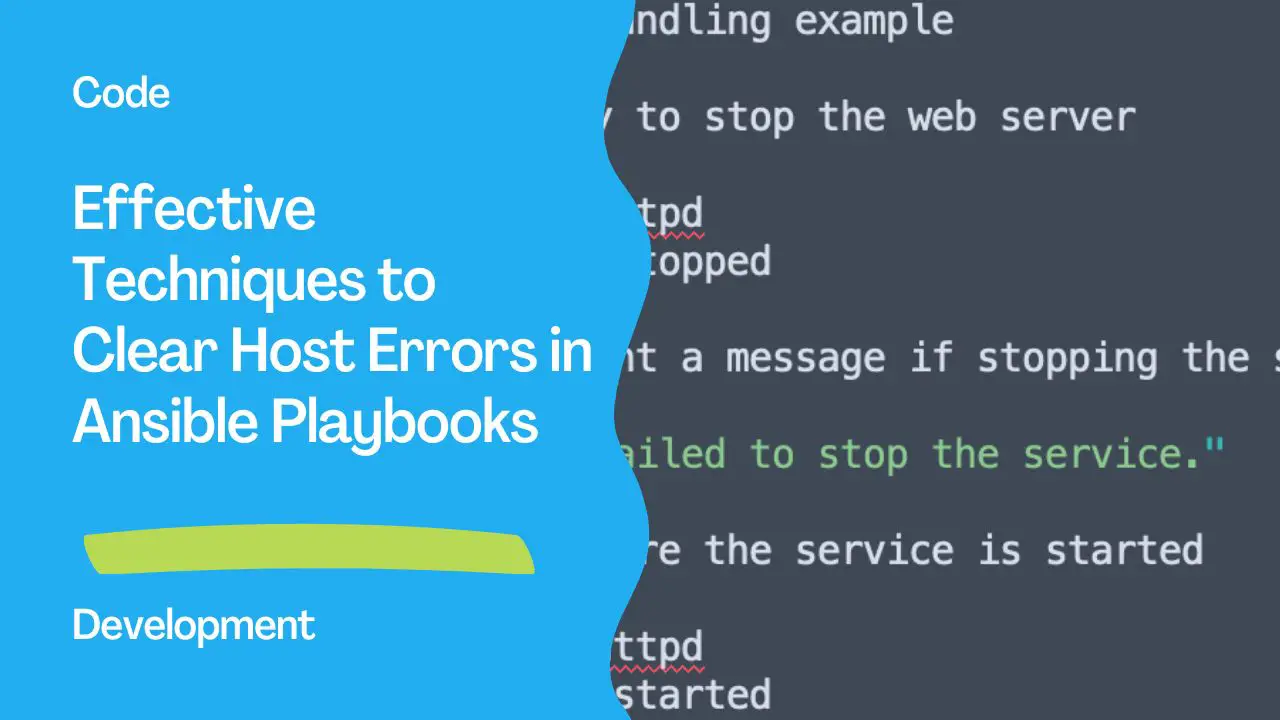
- name: Error handling example
block:
- name: Try to stop the web server
service:
name: httpd
state: stopped
rescue:
- name: Print a message if stopping the service fails
debug:
msg: "Failed to stop the service."
always:
- name: Ensure the service is started
service:
name: httpd
state: started
- Use the
failed_whenConditional:
failed_when directive allows you to specify custom failure conditions for tasks. This can be used to clear or handle host errors based on specific output or conditions.
- name: Check for a specific file
stat:
path: /etc/some_file
register: result
- name: Fail if the file is not present
debug:
msg: "The file is present."
failed_when: result.stat.exists == false
- Retry Failed Hosts:
--limit and --retry options. You can rerun the playbook against the failed hosts captured in the *.retry file.
ansible-playbook site.yml --limit @/path/to/failed.retry
- Conditional Handling with
when:
when directive to conditionally execute tasks based on the state of the host or task outcomes. This can be combined with error conditions to handle host errors more gracefully.
- name: Create a file only if previous command failed
command: /bin/false
register: command_result
ignore_errors: yes
- name: Touch a file
file:
path: /tmp/somefile
state: touch
when: command_result is failed
See also: Ansible extra-vars: Pass Variables via Command Line (--extra-vars Guide)
Clearing Host Errors
Clearing host errors effectively can mean resetting the state of the host in your inventory or ensuring that playbooks handle error conditions gracefully without manual intervention. For example:
- Reset the Host State Manually:
- Use the
meta: clear_host_errorsModule:
meta module in Ansible includes a special action called clear_host_errors that can be used to reset the error state of a host during playbook execution.
- meta: clear_host_errors
This clears the error status of a host so subsequent tasks will be executed on it, regardless of any previous failures.
Best Practices for Handling Host Errors
- Log and Monitor Errors:
- Graceful Degradation:
- Retry Mechanisms:
- Automate Recovery Actions:
rescue blocks or subsequent tasks to automate recovery actions, such as restarting services or re-running failed commands.
By following these practices, you can ensure that your Ansible automation is resilient and robust, capable of handling host errors effectively without manual intervention.
This article should provide a comprehensive overview of managing and clearing host errors in Ansible. For more detailed examples and use cases, refer to the relevant Ansible documentation and resources.
See also: Ansible troubleshooting - Error: name[template]
Related Articles
Category: troubleshooting